
- What you need versus what you’ve got
- The need for speed
- More and more data
- Good things come in small packages
Once communications service providers (CoSPs) have decided on their data strategy and priorities (see The end is where to begin with the data life cycle), their next step is figuring out which data needs to be acquired from where to achieve their desired outcomes. The rapid proliferation of IoT devices – and the data they generate – will affect where the data is ingested and processed, which in turn has big implications for the entire data life cycle (see diagram below) and the connectivity between the network’s core and edge.
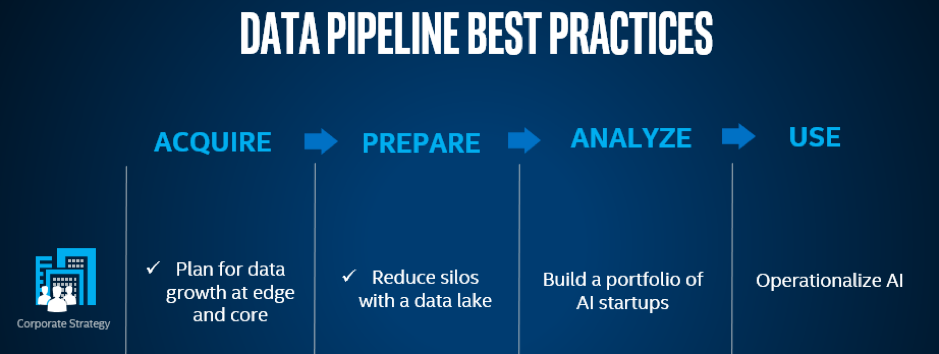
Gartner predicts there will be 5.81 billion connected devices by 2020 (see table below), and IDC forecasts that will rise to 41.6 billion devices in the field by 2025, generating 79.4ZB of data.
IoT Endpoint Market by Segment, 2018-2020, Worldwide (Installed Base, Billions of Units)
|
Segment |
2018 |
2019 |
2020 |
|
Utilities |
0.98 |
1.17 |
1.37 |
|
Government |
0.40 |
0.53 |
0.70 |
|
Building Automation |
0.23 |
0.31 |
0.44 |
|
Physical Security |
0.83 |
0.95 |
1.09 |
|
Manufacturing & Natural Resources |
0.33 |
0.40 |
0.49 |
|
Automotive |
0.27 |
0.36 |
0.47 |
|
Healthcare Providers |
0.21 |
0.28 |
0.36 |
|
Retail & Wholesale Trade |
0.29 |
0.36 |
0.44 |
|
Information |
0.37 |
0.37 |
0.37 |
|
Transportation |
0.06 |
0.07 |
0.08 |
|
Total |
3.96 |
4.81 |
5.81 |
Source: Gartner (August 2019)
It is immediately clear that not all this data can – or needs – to cross the network to reach centralised compute and storage resources. Instead, much of the processing will happen at the edge, in the interests of speed and cost. Sending huge amounts of data from the edge of the network to the core is expensive, slow, and sometimes pointless or not desirable.
What you need versus what you’ve got
A good example of this is a smart city application where the point of the exercise is to count the number of pedestrians or cars or cyclists to better understand usage patterns, accident hotspots or for planning purposes.
Here the questions the city authority, is trying to answer is ‘how many’ and ‘when’, not ‘who’. The video stream can be processed right next to the camera in real-time and discarded, not recorded. The information gleaned – which is a fraction of the volume of the original video stream traffic – can be sent back to the data platform periodically, avoiding busy times on the network.
Paring that raw data down to the useful information it contains means it should be easier to combine it with other data sets from other sources, such as air quality, temperature and hospital admissions for those with breathing difficulties, for instance.
The information could also be useful historically, such as to compare traffic levels in a year or two years’ time, or to identify seasonal shifts in patterns.
Discarding the video as it is processed at the edge has another benefit too: there are potential privacy concerns if the video were sent across the network for central processing and storage, regarding car registration plates and facial recognition. Sending only aggregated, anonymous information avoids those issues too.
Hence, depending on the nature of the application and the information required, it’s important to understand which data you need to achieve your business or operational goal, as opposed attempting to transport, process and store all the data you amass. In many use cases, less is most definitely more.
The need for speed
Edge will be particularly important for applications that need the data processed fast enough to be actionable in real time or near real-time, such as the factory of the future.
Here edge processing will allow ever greater degrees of automation, flexibility and precision, particularly when used in conjunction with 5G, reducing downtime and supporting applications like predictive maintenance.
Vodafone has worked with the electric microcar maker, e.GO Mobile, as Erik Brenneis, CEO of Vodafone Global Enterprise, explains: “At Vodafone, we worked with e.GO to connect machines in an 8,500m2 site using a private ‘5G ready’ network, rather than Wi-Fi, in a world first. Crucially, this connected factory means that e.GO’s development team can adjust factory settings at the touch of a button, allowing them to roll out new designs at speed.”
“The new e.GO electric car factory took just two years to develop and saved the company millions of euros. Looking ahead, the team will be able to keep up with demand for new designs with a robust and adaptable factory floor.”
Günther Schuh, CEO, e.GO Mobile, describes the factory as “Industry 4.0”, although somewhat surprisingly humans, not robots, assemble the cars. To maximise flexibility, the smallest components and tools are all wirelessly networked – not the sort of data that needs to traverse the cloud every time an item is used or moved. This makes production extremely cost efficient, by automating the flow of information and “transparency” – being able to see immediately and at all times where everything is.
More and more data
As more data is created, the role of edge will become ever more important: 91% of today’s data is created and processed by centralised data centres, Gartner forecasts that by 2022 about 75% of data will to be analysed and acted on at the edge – not forgetting the proviso only to acquire and process the data you need, rather than all you have.
CoSPs will need to deploy ever greater intelligence at the edge of their own networks and those they run for customers to extract the value from data affordably. As 5G enables more applications and services through attributes like network slicing and microservices, not only will the volume of data keep rising, but the resources needed at the edge will become more complex and varied.
Good things come in small packages
Services and applications will need different balances of performance, power consumption and size, and of course that balance might vary over time as other factors come into play and IoT use cases mature.
That doesn’t mean centralised resources will be obsolete – it will remain a good place for applications that exploit historical data, for example or to combine data sources – rather, optimising connectivity between the edge and core will be fundamental to the success of the entire data pipeline. In short, the trick is to have the right connectivity available (in terms of capacity, speed and coverage) in the right place at the right cost, with flexibility too.
The Intel Xeon Scalable processor architecture was created for this scenario. It offers solutions for all points, from the data centre core, to the edge and right to the endpoint device. The processors are designed to support the largest variety of high-demand applications and services: for instance, If you need data centre-class capabilities at the outermost edge, the new Intel Xeon-D processor leverages that architecture on an optimised, dense, lower-power system-on-a-chip (SoC) for locations for where there are space and power constraints.
If small physical size, very low power and the ability to operate in extreme temperatures are required, then Intel Atom processors are purpose-built for those edge use cases.
As all companies strive to become more data-driven, the flexibility to optimise their assets at any time and all the time will perhaps prove to be the single biggest competitive differentiator.
This is the second article in a series of four looking at the data lifecycle. You can read about the start of the cycle here and the next in the series, on applying analytics and AI to the data for specific purposes here - The big data clean-up – from silos into the lake.
Email Newsletters
Sign up to receive TelecomTV's top news and videos, plus exclusive subscriber-only content direct to your inbox.



